
Cloudflare发生故障,今天香港时间下午再度出现大规模问题,全球数百万网站同时抛出500 服务器内部错误,受影响的服务包括Dcard、Canva、Zoom等常用平台,而Cloudflare本身盘前股价一度急挫近6%,投资者对其稳定性敲响警钟。更令人震惊的是,这已是该公司一个月内第二次发生重大事故,现代网络架构的脆弱性再次暴露在公众面前。

半小时故障 数百万网站齐中招
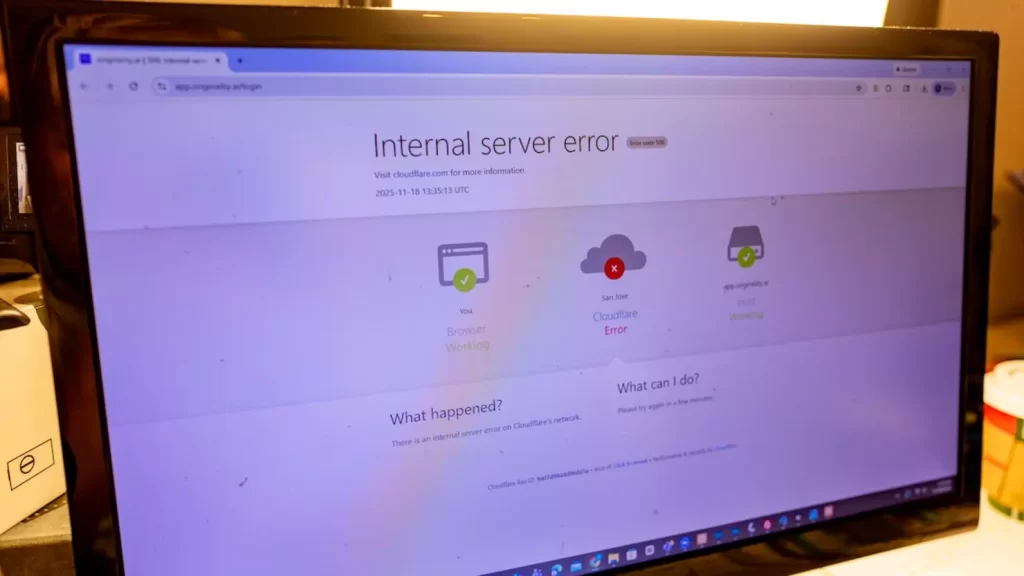
今日下午,香港和亚洲用户陆续发现 Dcard、Canva、Zoom 等服务无法正常访问,页面弹出 500 服务器内部错误。Cloudflare 在状态页面确认,此次事故源于其 Dashboard 及相关 API 出现服务问题,导致使用这些服务的网站请求失败或直接报错。事故持续约半小时后,Cloudflare 表示已实施修复措施并持续监控系统状态。对一般用户而言,眼前的感受就是 所有网站都无法访问,无论是开 Zoom 见客、用 Canva 设计社交媒体图片,还是上论坛讨论,全都瞬间断线。
__PLACEHOLDER_8__
一个月内发生两起大型事故,脆弱的骨干再次敲响警钟。
值得注意的是,这已经是 Cloudflare 一个内月内第二次大型事故。11 月中旬,该公司因 Bot Management 配置错误导致大量流量路由崩溃,当时同样造成网站全面响应 500 错误,规模非常惊人。Cloudflare 作为全球最大之一的 CDN 和网络安全供应商,为数以百万计的网站提供内容传递、DDoS 防护、DNS、反向代理等服务,简单来说就是 互联网背后的水管与闸门。随着越来越多的网站集中使用同一基础设施供应商,任何内部错误或配置更新失误,都可能引发全球连锁反应,这次甚至连监测服务状态的 DownDetector 自己都一度无法访问。
盘前股价急剧下跌,可靠性被打上了问号。
事故发生后,Cloudflare 在美股盘前立刻受到压力,股价一度下跌近 6%,之后跌幅略有收窄。尽管 Cloudflare 依然是云安全和 CDN 领域的重要玩家,市值约为 750 亿美元,但连续发生两次大型事故,不可避免地给其可靠性带来疑问。这次故障初步确认并非外部攻击,而是内部更新引发的错误流程,和早前 11 月的配置问题同样属于自己搞错自己,这种性质对长期投资者来说更加敏感。市场担心,如果 Cloudflare 在变更流程、测试机制和冗余设计上没有明显改善,类似事故未来可能会重演,届时将对品牌和股价造成更深远的打击。

香港企业与用户如何应对
对于香港本地用户及网店老板来说,Cloudflare 出事未必会立刻让人转变供应商,但一定会让大家重新审视风险。很多中小企业、网店,甚至内容网站都使用 Cloudflare 作为 DDoS 防护、SSL、CDN,原因在于价格合理和设置简单,但这次事件再次证明了平靚正的背後其實隱藏著一個單一的故障點。。对技术团队而言,下一步应该考虑多云及多 CDN 策略,比如关键服务同时配置第二条直连路线或备用 DNS/CDN,至少在某一供应商出现大规模故障时,可以迅速将部分流量切走,减少对用户的影响。而一般用户虽然未必能选择背后使用哪家 CDN,但至少要意识到,当无法访问某个网站时,问题往往不在于你的路由器,而是在全球骨干网络层面出现故障,避免无谓地重启数据机或责怪 ISP。
Cloudflare 当机后如何自救
Cloudflare 在最新更新中表示,这次 Dashboard/API 故障已修复,相关服务陆续恢复正常,并强调将持续监控系统状态,以防止间歇性问题再度出现。不过,经历了 11 月和 12 月两次大规模事故后,市场更关心的是 Cloudflare 如何改变内部变更流程,比如加强 Canary 测试、限制高风险时间的更改,或者将关键模块拆分,以避免一个错误拖垮整个网络。对香港读者来说,短期内最实际的做法是:遇到 App 或网站突然出现大规模 500 Error,不妨先查看监控平台或社交媒体的相关关键词,看看是否Cloudflare 又出事了,而不是盲目重装 App 或指责本地 ISP。中长期如果你负责网站或 App,就真的要开始思考一套CDN 出事 计划 B,否则每次全球性故障,你的生意也将被迫按下暂停键。

