
Cloudflare 當機,今日香港時間下午再度出現大規模故障,全球數百萬網站同時拋出「500 Internal Server Error」,受影響服務包括 Dcard、Canva、Zoom 等常用平台,而 Cloudflare 本身盤前股價一度急挫近 6%,投資者對其穩定性響起警號 。更令人震驚的是,這已是該公司一個月內第二次大型事故,現代網絡架構的脆弱性再次暴露人前 。

半小時故障 數百萬網站齊中招
今日下午,香港及亞洲用戶陸續發現 Dcard、Canva、Zoom 等服務無法正常訪問,畫面彈出「500 Internal Server Error」。Cloudflare 在狀態頁面確認,今次事故源於其 Dashboard 及相關 API 出現服務問題,導致使用這些服務的網站請求失敗或直接拋錯 。事故持續約半小時後,Cloudflare 表示已實施修復措施並持續監控系統狀態 。對一般用戶而言,眼前感受就是「所有網站都上不了」,無論開 Zoom 見客、用 Canva 設計社交媒體圖片,還是上論壇討論,全都瞬間斷線 。
一個月兩次大型事故 脆弱骨幹再敲警鐘
值得留意的是,這已是 Cloudflare 一個月內第二次大型事故 。11 月中旬,該公司因 Bot Management 配置錯誤令大量流量路由崩潰,當時同樣造成網站全面回應 500 錯誤,規模相當驚人 。Cloudflare 作為全球最大之一的 CDN 及網絡安全供應商,為數以百萬計網站提供內容傳遞、DDoS 防護、DNS、反向 Proxy 等服務,簡單來說就是「互聯網背後的水喉同閘門」。當愈多網站集中使用同一間基礎設施供應商,任何內部錯誤或配置更新失誤,都足以引發全球連鎖反應,今次甚至令監察服務狀態的 DownDetector 自己都一度無法訪問 。
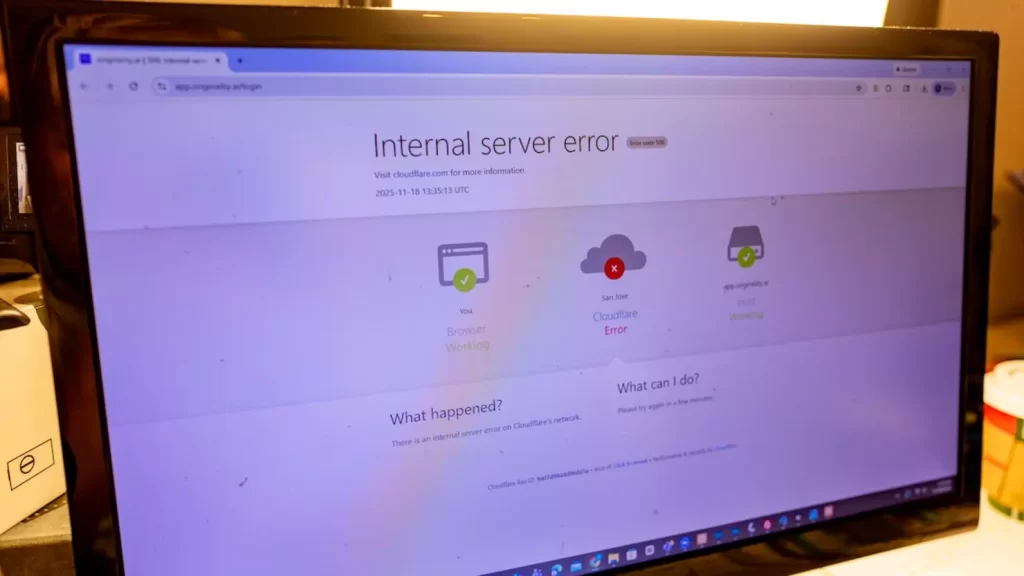
盤前股價急挫 可靠性被貼上問號
事故一出,Cloudflare 於美股盤前即時受壓,股價最初一度下挫近 6%,之後跌幅略為收窄 。雖然 Cloudflare 仍然是雲安全及 CDN 版圖中的重要玩家,市值約 750 億美元,但接連兩次大型事故無可避免為其「可靠性」貼上問號。今次故障初步確認並非外來攻擊,而是內部更新引發的錯誤流程,與早前 11 月的配置問題同樣屬「自己搞錯自己」,這種性質對長線投資者而言更加敏感。市場擔心,如果 Cloudflare 在變更流程、測試機制及冗餘設計上無明顯改善,類似事故未來可能再重演,屆時對品牌及股價都會造成更深遠打擊 。

香港企業與用戶如何應對
對香港本地用戶及網店老闆來說,Cloudflare 出事未必會即刻令人轉換供應商,但一定會令大家重新檢視風險。好多中小企、網店,以至內容網站都使用 Cloudflare 做 DDoS 防護、SSL、CDN,一來價格合理,二來設定簡單,但今次事件又一次證明「平靚正背後都有單一故障點」。對技術團隊而言,下一步應該考慮多雲及多 CDN 策略,例如關鍵服務同時配置第二條直連路線或備用 DNS/CDN,最少當某一供應商出現大規模故障時,可以將部分流量快速切走,減低對用戶的影響 。而一般用戶雖然未必選擇到背後使用哪間 CDN,但起碼要意識到,當開不了某個網站,問題好多時不在你的路由器,而是全球骨幹層面出事,避免白白重啟數據機或責怪 ISP。
Cloudflare 當機下一步如何自救
Cloudflare 已在最新更新中表示, 今次 Dashboard/API 故障已經修復,相關服務陸續恢復正常, 並強調會持續監察系統狀態, 防止再有間歇性問題出現 。不過, 在經歷 11 月一次、12 月又一次的大規模事故後, 市場更關心的是 Cloudflare 如何改變內部變更流程, 例如加強 Canary 測試、限制高風險時間更改、或者將關鍵模組拆分, 避免一個錯誤拖垮整個網絡 。對香港讀者來說, 短期內最實際的做法是:遇到 App 或網站突然大面積 500 Error, 不妨先查看監察平台或社交媒體關鍵字, 看看是否「Cloudflare 又出事」, 而不要盲目重裝 App 或指責本地 ISP。中長期如果你負責網站或 App, 就真的要開始思考一套「CDN 出事 Plan B」, 否則每次全球 Outage, 你的生意就同樣被迫按下暫停鍵。